Web agents on 200M+ POI data
How we evaluate agent performance at scale, the tooling patterns we've adopted, and lessons learned from building production-grade enrichment pipelines on over 200 million data points.
Mikhail
Member of Technical Staff @ Reprompt

Introduction
Reprompt manages over 200 million data points across the globe, serving enterprise customers with enrichments on both their data and our proprietary datasets. Scaling web agents to this volume requires trust in the system, fast iteration, and grounding outputs on verifiable sources. This article covers how we evaluate agent performance at scale, the tooling patterns we've adopted, and the lessons learned from building production-grade enrichment pipelines.
How our AI agents work
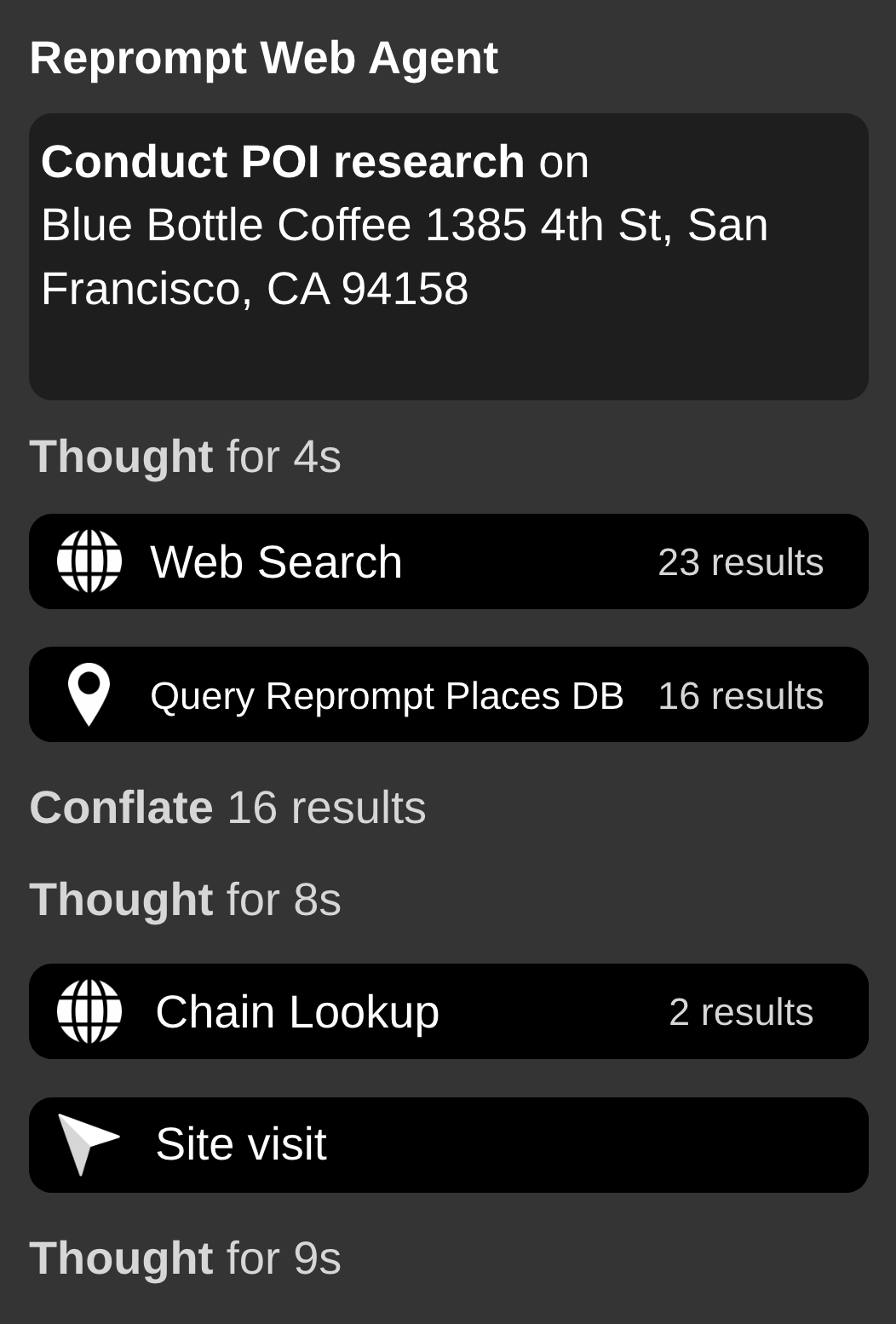
Our agents retrieve and synthesize information from multiple web sources—search engines, business directories, official websites, and social media profiles. Given a POI (Point of Interest), an agent queries relevant sources, extracts structured data, and returns enriched attributes like business status, opening hours, or official website URL. The agent decides which tools to call, in what order, and when it has enough information to return a result.
Fast evaluation and iteration speed
The bottleneck isn't infrastructure-it's the agent's ability to find the right source, extract the right fact, and know when to stop. A request that hits three irrelevant pages before finding an official website costs more and risks hallucination. Our metrics reflect this: fill-rate, precision, and stability.
Fill-rate is a measure of percentage of inputs that receive a non-empty response
Precision is a measure of the agent's response to an annotated set of outputs. This is the primary metric for determining accuracy.
Stability is a measure of how often the agent returns the same answer across repeated runs. If responses are grounded on findings from the internet, we expect high stability despite the inherent property of non-determinism in LLMs. For attributes like business status, opening hours, or official website URL, these facts should have high stability. This metric is common for responses with a defined set rather than qualitative text outputs.
Fill-rate and precision trade off. Larger models and longer agent loops improve precision but are more likely to abstain when confidence is low, reducing fill-rate.
Lastly, codifying the domain's knowledge into the agent's prompts and procedure of tool-calling is incredibly important.
For example, if an agent knows a POI is categorized as "fast food" and named "McDonald's," the agent can skip web search tools and directly visit the chain's site for the store locator. A local restaurant with the same name requires a different approach—broader search, cross-referencing address and phone number.
This kind of domain logic lives in the prompts and tool-selection rules, not the model itself. The metrics and close familiarity to the domain enable meaningful measurement and direction for iteration.
Lessons we've learned along the way
Building grounded agents is hard both in execution and evaluation. We've tried various approaches, but the common thread is the value lies in the tools, not the framework orchestrating them.
One pattern we've found useful: wrap web content and a lightweight LLM together into a single-purpose tool. Rather than dumping full webpage content (often tens of thousands of tokens) into the agent's context, the tool extracts only what's relevant. The agent receives processed information instead of raw HTML. This reduces cost and hallucinations.
To handle scale, we process requests asynchronously. Incoming requests are queued and workers process them independently. This allows us to handle millions of POI enrichment requests without blocking, and to refresh our proprietary data on a continuous basis.
What's next
The patterns described here—context-rich tooling, orchestration over monolithic agents, async job processing—were built for factual enrichments like hours and business status. They generalize. KYB verification requires correlating data across registries and web sources. Unit entrances require spatial reasoning over satellite imagery and street-level data. Geofencing requires boundary inference from multiple signals. These are harder problems we're tackling in 2026, but the evaluation framework (fill-rate, precision, stability) and the architectural patterns remain the same. The complexity moves into the tools and the reasoning, not the infrastructure.
Ready to get started?
Try Reprompt today and transform your location data.