Building a location deep research agent
Deep research is a powerful tool, but it doesn't map well to location intelligence. Inside Reprompt's Deep Research Agent architecture custom-built for places research.
Rob Balian
CTO @ Reprompt

The deep research wave
Over the last 18 months, "deep research" has gone from a research-paper trick to a feature in nearly every major chat product. OpenAI, Anthropic, Perplexity, Gemini, and several open-source projects now ship some version of a deep research agent: a system that plans, browses, summarizes, and returns a cited report.
We've experimented with many of these systems. They are useful for open-ended research, but they are not particularly well suited for places research. At Reprompt, we need to answer a narrower question at production scale: what is true about this place, right now, and how do we know?
Anatomy of a general-purpose deep research agent
The standard Deep Research pattern is a planner loop that breaks the request into smaller questions, then spawns many search + browse + summarize subagents. Each subagent gets a different prompt and an isolated context window, so the system can explore multiple branches in parallel.
A compiler then combines the results, removes duplicates, resolves conflicts, attaches citations, and formats the final report. In stronger implementations, the compiler is not the end of the process. If the evidence is thin or contradictory, it can send the system back through the planner loop and request more targeted research.
Location research is a specific and challenging problem
The generic deep research pattern breaks down when the unit of work is not "write me a report," but "verify this field for this place."
Cost and Speed at Scale: Reprompt keeps over 200M places up to date. A typical Deep Research request from the AI labs is roughly $5 and takes 10 minutes. Seeing the AI run through a human process of searching, thinking, and compiling is very cool but breaks when you need millions of reports. So for global scale we need a faster and more cost-efficient alternative.
Entity Resolution: Places queries tend to have challenging duplicates that normal Deep Research agents have a hard time with. Renamed, misnamed, translated, moved businesses, and sublocations like malls further compound the problem.
To solve this, we include a full entity resolution step before our agentic research. Information can only be used if it can be positively associated with the correct place.
Data Reliability: Some markets have reliable official websites. Others rely more heavily on social profiles, government registries, delivery platforms, or regional directories. Generic agents actually over-research, including data that is irrelevant or even false.
Output Structure and Taxonomy: Finally, the output needs to be structured. A deep research report looks really impressive, but for places we want consistent, structured data fields, a confidence level, and a source that can be audited later.
Reprompt's Deep Research Agent architecture

Given a semi-structured input POI with name, approximate address or coordinates, and sometimes a category hint, the agent produces a verified structured record:
| Attribute Category | Description |
|---|---|
| Reprompt canonical Place ID | Unique identifier for the place in Reprompt's system |
| "Core" place attributes | Structured, core attributes relevant to any place |
| name | |
| categories | |
| address | |
| phone numbers | |
| opening hours | |
| official website and social URLs | |
| operating status | |
| Reasoning, confidence, and citations | Explanation, confidence score, and citation(s) for each data field |
The first step is entity resolution: is this the right place? Before the agent can answer "what time does this restaurant open on Sunday?" it has to distinguish the target from similarly named businesses, stale listings, franchise locations, moved locations, and unrelated places at nearby addresses. We map this where possible to a Reprompt canonical Place ID.
Once the entity is resolved, the planner loop chooses the right tools and research branches. Some branches look like a generic search + browse + summarize subagent. Others are specific to Reprompt, such as looking at navigation routing, imagery, property information, or querying partner databases.
The agent then reranks and categorizes sources. This matters because source quality is not universal. A source that is useful for category discovery may be unacceptable for opening hours. A source that is reliable in one country may be noisy in another. The system needs to know which evidence can support which field.
Finally, the compiler deduplicates evidence, resolves conflicts, generates citations, and emits a structured output matching our schema. If the evidence does not meet the threshold for a field we return null instead of providing a guess.
Creating new attributes with the same agent
The agent excels at researching the "core" place attributes, but we use the same harness to generate customer-defined attributes defined by customers. By using the same harness with built-in tools and place knowledge, we can spin up a new attribute for an entire dataset without changing code.
An example site selection use case: Beyond name and hours, we might want the pump count, whether diesel is sold, and the signage type and the site's visibility from the road. Some of those can never be answered from text alone. We use imagery research which is a selected tool from the planner subagent. The agent resolves the place, then reads the actual scene from aerial and street-level imagery alongside the open web.

A pylon sign's height, the number of pump housings, a corner lot versus mid-block, a car-wash bay — these come from the pixels, with the supporting imagery attached as the citation. The same harness with new field.
Creating a new attribute with just a prompt
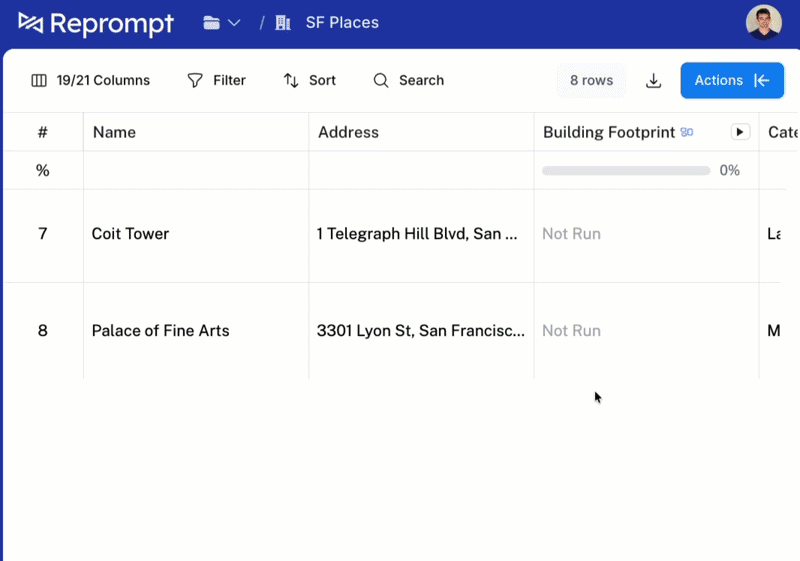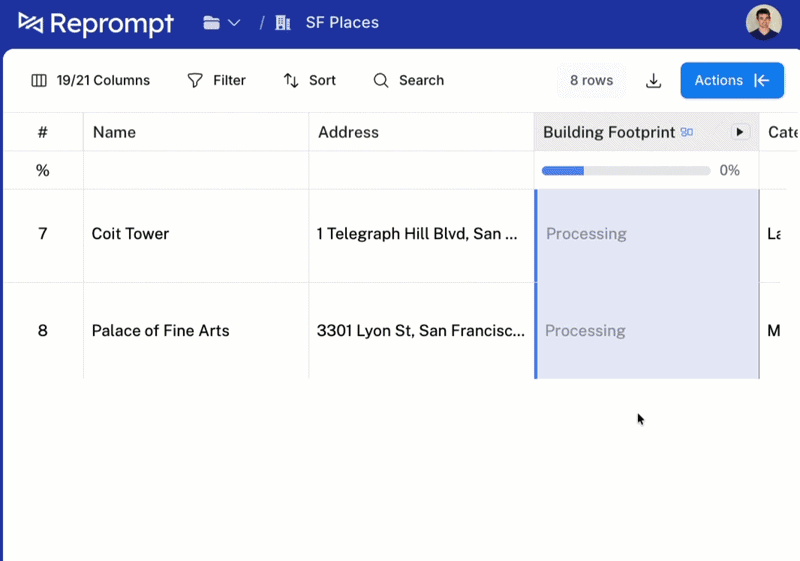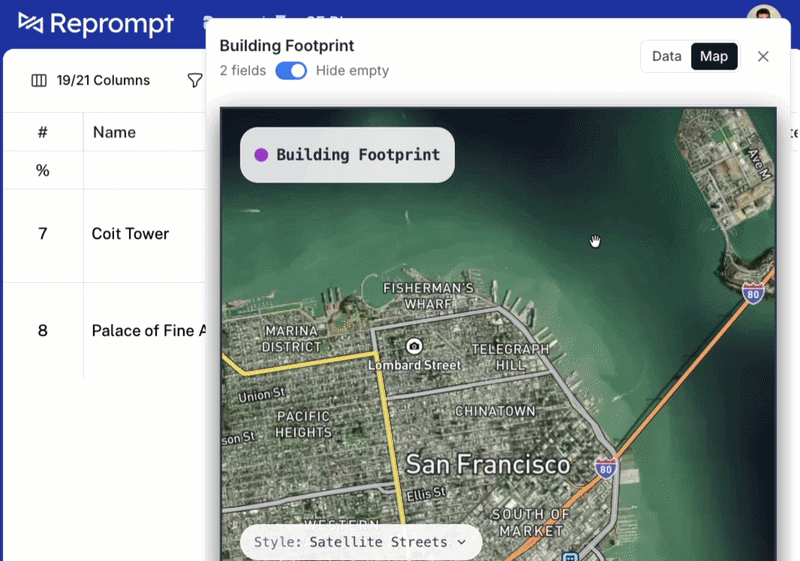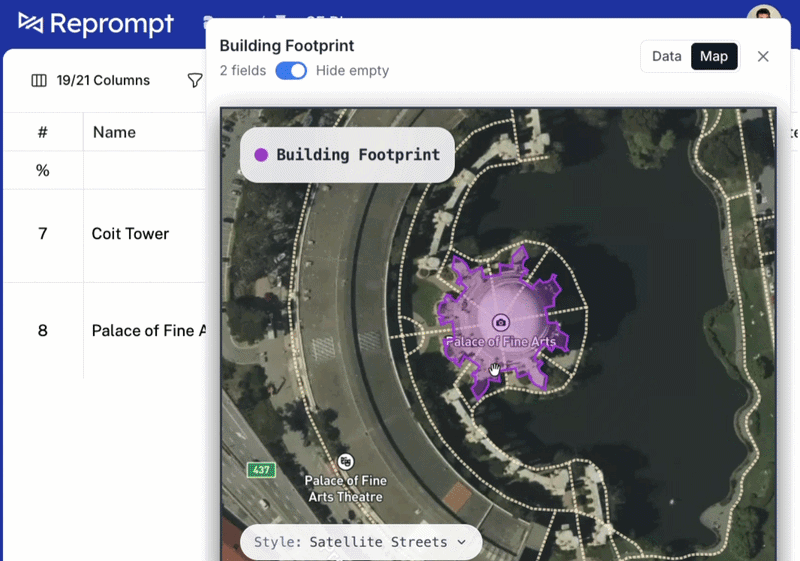
Most customers use deep research enrichments via the api, but we also created a table UI that allows running both pre-defined and custom attributes. Building a new attribute and running it across 1000's of rows only requires a prompt in the table.
Unique challenges for location intelligence
LLMs are trained primarily on English text, but we do research across global places. Quite a few parts of our agent are country-specific:
Source ranking and reliability: In the source ranking step, we use a custom source ranking by country based on which sources have provided accurate information for past evals.
Address formatting and validation: LLMs across the board perform poorly on address formatting and validation. We use a custom address formatter and validator that tuned for each country's address format.
Language and multi-language support: Different LLM models perform differently across languages. GPT models for instance perform poorly on reading or writing Thai or Arabic script. Abbreviations are different by country.
Self-evaluation and improvement: Place data changes all the time, so having a stable groundtruth benchmark is difficult. A place that is open in the "GT" may have closed or changed their name. We built an evaluation loop that uses multiple agents to evaluate the same place to create a more stable up-to-date benchmark to test agent changes against.
Global scale is a challenge for LLMs
Researching across millions of web artifacts uses a lot of tokens. To date, we've processed over 4 trillion LLM tokens. To handle this scale, we've invested in an evaluation loop that runs at maximum intelligence and depth first, then determines which agent tasks can use faster and cheaper models.
For example, a subagent might use a faster model to summarize a web page, sending only the relevant parts back to the main agent. This reduces cost and risk of hallucinations.
Unexpected: The cost of hosted "mini" or "lite" models is exponentially increasing year over year as the new models get smarter and providers phase out older models.

We're constantly evaluating self-hosted and open source models to find the best balance of cost, accuracy, and speed.
Workflows -> Agent -> Harness
Our journey to build the Deep Research Agent followed a pattern we've seen across the industry: workflows -> agent -> harness.
Over time, as models become more capable of long-term trajectories and reasoning, more business logic is moved to the agent and less built into code.

Workflows: A series of hard-coded, deterministic steps. Logic and operations are explicitly defined in code and followed by the agent, but the agent’s intelligence is not actively applied—steps are executed, not reasoned about.
Agents: Intelligent agents with access to a broad set of tools—web search, image analysis, API calls—and the ability to plan and reason. Agents make decisions, execute actions, and produce structured outputs defined in code.
Harnesses: A full computer environment with controlled access to tools (LLM, command line, storage, and networking). Harnesses actually have fewer tools at their disposal compared to agents. Instead, a harness can solve tasks by writing custom code, storing intermediate results, and deciding the output format at runtime.
Our system leverages the strengths of both agents and harnesses, investing in domain knowledge, tools, and flexible task execution for novel use cases.
What's next
We are continuing to push this architecture in three directions: better entity resolution, stronger country-specific evidence policies, and faster evaluation loops.
Deep research agents are powerful, but the broad version of the pattern only scratches the surface. For production location intelligence, the hard part is not browsing more pages. It is knowing which evidence is allowed to answer which question, accessing the right sources with location-speficic tools, and returning a structured result customers can trust.
Ready to get started?
Try Reprompt today and transform your location data.